A corporate physical security strategy is the "why + what + how" behind every guard, camera, badge reader, and response process across the enterprise. It connects day-to-day protection (people, facilities, assets, and operations) to business objectives, risk tolerance, and the reality that modern physical security is increasingly software-driven and interconnected with IT and cybersecurity.
In practice, a corporate physical security strategy is what prevents physical security from becoming a patchwork of site-by-site decisions. Mature organizations formalize security strategy and review it through leadership forums and governance cycles (e.g., executive oversight committees, defined policy sets, audit programs, and integration requirements for acquisitions).
This article explains proven best practices for building a corporate physical security strategy that scales globally, drives consistent outcomes, remains resilient during disruptions, and builds leadership confidence through measurable performance and clear operational ownership.
Summary of key corporate physical security strategy best practices
The table below summarizes the eight corporate physical security best practices this article will cover in more detail.
| Best practice | Description |
|---|---|
| Write a clear strategy charter (scope, outcomes, boundaries). | Understand what corporate security owns, what it influences, and what success looks like. |
| Establish governance and decision rights for standards, funding, and exceptions. | Explain how enterprise security decisions are made and enforced: who approves standards, how exceptions are handled, how priorities are funded, and how assurance/audits validate compliance. |
| Translate risk into enterprise baselines using a consistent risk-to-requirements model. | Use a repeatable approach to classify facilities/critical assets and derive minimum control baselines and enhancements. |
| Design a scalable Target Operating Model (TOM) and service ownership. | Define who delivers which security services (corporate vs regional vs site) and how work flows across departments. |
| Create a technology strategy: architecture principles plus managed-fleet operations. | Standardize how systems connect (events, data, evidence), how the security tech estate is inventoried/monitored/maintained, and how lifecycle (EOL/EOS) is managed across multi-vendor environments. |
| Build resilience and continuity requirements into the strategy. | Explain minimum viable security services, degraded-mode operations, and recovery sequencing. |
| Operationalize compliance and privacy globally. | Establish privacy-by-design guardrails for video/access data, retention, evidence handling, and regional legal variation. |
| Run strategy with executive metrics, benchmarking, and a living roadmap. | Create a measurement and improvement system: scorecards, maturity benchmarking, quarterly priorities, and a strategy refresh cycle. |

Monitor the health of physical security devices and receive alerts in real-time

Automate firmware upgrades, password rotations & certificate management

Generate ad hoc and scheduled compliance reports
Write a clear corporate physical security strategy charter (scope, outcomes, boundaries)
A clear corporate physical security strategy charter provides leadership with a shared reference point and the security team with a practical filter for subsequent decisions. Capture it on one page, validate it with partners, and use it as the anchor for the rest of the strategy.
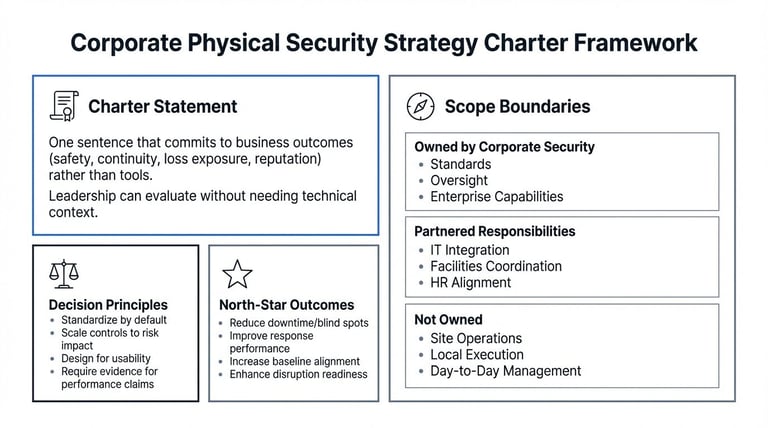
Corporate physical security strategy charter framework
Write a single charter statement executives can reuse
Draft one sentence that commits to business outcomes (safety, continuity, loss exposure, reputation) rather than tools. If the statement includes cameras/guards/readers, rewrite it until leadership can evaluate it without needing technical context.
Set clear ownership boundaries before execution begins
State what corporate security owns, what sites execute, and what is partnered with IT/Facilities/HR/Legal/Privacy. Make the handoffs explicit in plain language so responsibilities don't get renegotiated during incidents or projects.
Run these as short working sessions with a draft ownership map and a few real scenarios (incident response, access changes, evidence export, new site build-out). Convert discussion into explicit handoffs and escalation paths, then document the decisions and get written confirmation to avoid relitigating ownership later.
Lock in decision principles that resolve future tradeoffs
Write a short set of operating rules (standardize by default, scale controls to risk/impact, design for usability, require evidence for performance claims). Keep them phrased so teams can apply them in real decisions.
Define north-star outcomes without naming solutions
Pick three to five outcomes that should improve year-over-year (downtime/blind spots, response performance, baseline alignment, disruption readiness). Keep them tool-agnostic and define the metrics and data sources after.
Tailor north-star outcomes to program maturity. For greenfield or fragmented programs, prioritize baseline consistency and closing major visibility gaps. For developing programs, focus on reducing exceptions and improving remediation speed. For mature programs, emphasize resilience performance, lifecycle predictability, and measurable risk reduction.
Validate the charter with partners, then publish it
Do a quick red-flag pass (remove org charts, system lists, project plans), confirm boundaries with partner teams, then share upward as the anchor for governance and execution.
Establish governance and decision rights for standards, funding, and exceptions
Once the charter is written, put governance in place immediately so the strategy can be executed consistently across sites. Treat this as a practical operating system: who sets standards, who approves change, how investments are prioritized, and how deviations are handled without creating long-term gaps.
Start by publishing a one-page decision-rights map that names who approves standards changes, funding decisions, and exceptions at corporate, regional, and site levels. Then standardize the inputs for those decisions: a simple funding prioritization rubric and a required exception packet (justification, risk accepted, compensating controls, owner, and expiry date). Use those two artifacts in a recurring governance cadence so approvals are consistent and deviations remain visible and time-bound.
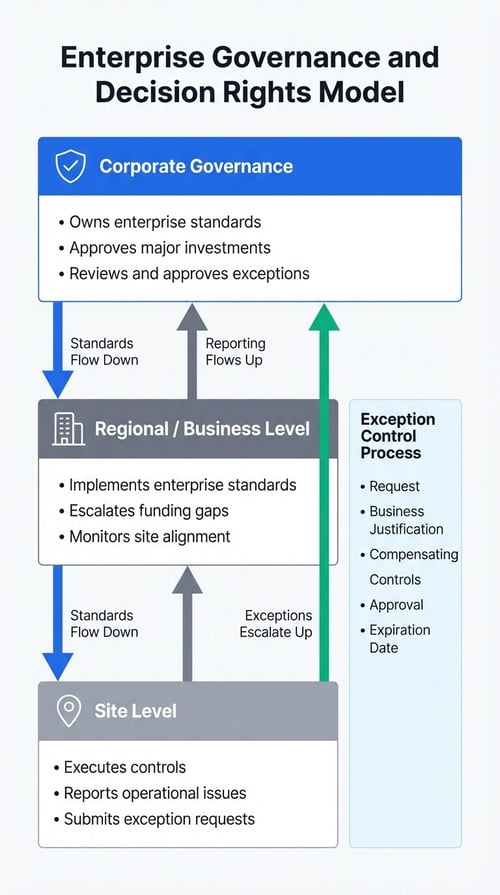
Enterprise governance structure defining standards ownership, funding authority, and exception control.
Assign owners and approval paths for standards
Name owners for policy/standards and document what can be decided locally versus what must be escalated. Keep enterprise standards controlled to prevent drift across regions.
Keep governance focused on consistency, not micromanagement
Use governance to verify alignment and close gaps, while leaving daily execution to the site. For example, imagine a regional office that meets baseline access control requirements but chooses a different guard shift pattern based on local risk.
Governance should confirm that required controls are present and functioning, not dictate staffing models or workflow details unless standards are being breached. Focus on whether baseline requirements are met, exceptions are approved, and remediation deadlines are being met. Allow sites flexibility in how they execute, as long as outcomes remain aligned to enterprise standards.
Use a repeatable model for funding decisions
Prioritize investments using a short set of criteria (risk exposure, business criticality, regulatory drivers, lifecycle condition). Clarify corporate vs site budget responsibilities and escalation thresholds.
Make exceptions visible, time-bound, and measurable
Require justification, compensating controls, an approver, and an expiry date for every deviation. Treat re-approval as mandatory to prevent exceptions from becoming a permanent risk.
Run assurance as a cadence, not a fire drill
Set a predictable assessment rhythm that checks implementation, exception status, and remediation progress. Focus on trends across sites to adjust standards and funding priorities, rather than reacting to isolated issues.
Use these reviews to prepare for budget conversations before funding cycles begin. Highlight recurring gaps, aging exceptions, repeated system failures, or sites consistently out of alignment, and translate them into business impact, operational disruption, safety exposure, regulatory risk, or reputational concern. Bring quantified trends instead of one-off incidents, and frame funding requests as risk reduction and stability improvements rather than technology upgrades. The right time to escalate budget discussions is when trends show sustained exposure, not after a single event.
Modern device management platforms can help by providing consistent, cross-site reporting that makes gaps and remediation progress easier to validate without relying on spreadsheets.
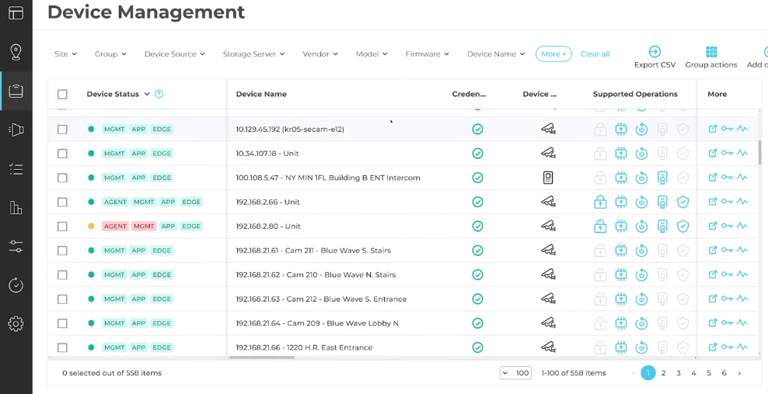
Centralized device management view supporting governance oversight and cross-site visibility. (Source)
Translate risk into enterprise baselines using a consistent risk-to-requirements model
Once governance is in place, define what each type of site is actually required to implement. Do not negotiate controls location by location. Translate risk into enforceable baselines that scale across the enterprise.
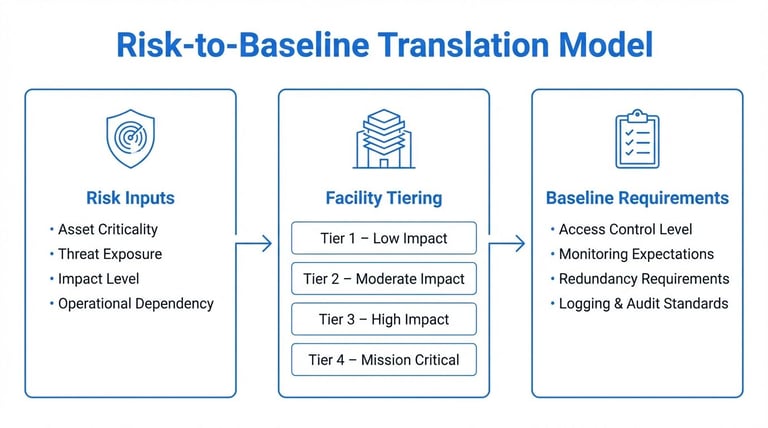
Risk-to-baseline model for defining tiered security requirements.
Apply one consistent risk lens
Use the same method to assess all facilities and critical assets. Evaluate what must be protected, credible threats, impact, and current exposure. Consider practical drivers such as the number of employees on site, the presence of executives or sensitive functions, the type of work conducted, the value and criticality of operations, regulatory obligations, and the potential impact of disruption.
Tier facilities and set minimum requirements
Group sites into tiers based on criticality and exposure. For each tier, define clear minimum requirements. Avoid vague recommendations; write requirements that are specific and enforceable. Tiering prevents over-securing low-risk sites and under-protecting high-impact operations.
Define the scenarios you design against
Identify the realistic scenarios your controls must withstand, such as unauthorized access to sensitive areas, disruption of critical operations, insider misuse, and targeted theft. Build these scenarios with stakeholders in short working sessions so the risk framing is shared: start with what the business cares about protecting (people, uptime, sensitive work), agree on the most plausible ways it could be disrupted, then define the minimum conditions the site must resist.
Capture the agreed scenario in one paragraph with a clear "success condition" (what must still work) and use it as the reference point when requirements are challenged. When pushback occurs, return to the scenario and test whether the baseline still meets that agreed success condition.
Confirm implementation and update over time
Require sites to validate that required controls exist and function. Keep validation practical and periodic. Update baselines when business operations, facility types, or threat exposure change. Route deviations through the formal exception process rather than adjusting standards informally.
Platforms like SecuriThings can support this step by helping teams confirm coverage and operational status across locations without manual tracking.
Design a scalable Target Operating Model (TOM) and service ownership
After baselines are set, assign ownership so they don't sit on paper. Start by mapping who is accountable at corporate, regional, and site levels, then define who runs each security service day to day.
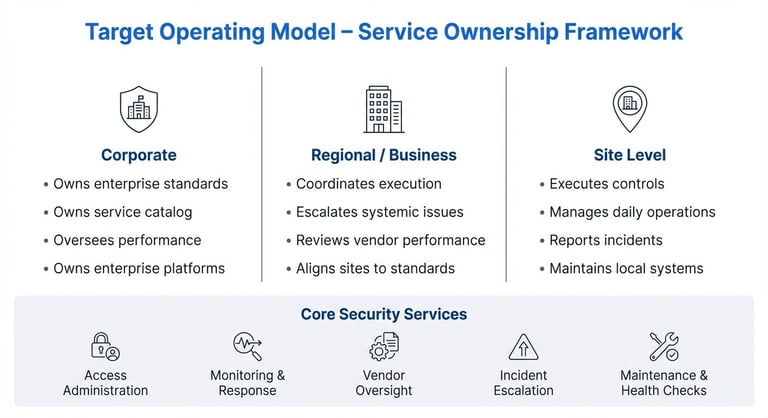
Scalable operating model for enterprise security service ownership
Define role boundaries across levels
Specify what corporate security owns versus what regional and site teams execute. Corporate should retain ownership of standards, oversight, and enterprise capabilities. Regional or site teams should manage day-to-day execution in accordance with those standards.
Build buy-in for the implementation by involving site leaders early and giving them a controlled way to shape how standards are applied. Run short working sessions with a few representative sites to validate workflows, identify friction points, and agree on what "good" looks like in practice.
Allow bottom-up input through a defined feedback loop: sites can propose adjustments to procedures or implementation patterns based on local realities, while corporate evaluates changes against the charter and baselines before standardizing them.
Assign ownership for each security service
Create a simple service catalog and assign a named owner to each function, such as access administration, monitoring coordination, vendor management, incident escalation, and maintenance oversight. Avoid shared or ambiguous ownership. If more than one team touches a service, define the primary accountable owner and the handoff points.
Clarify third-party and vendor accountability
Define how guard forces, monitoring providers, and integrators are managed as operational partners. Set SLAs, escalation paths, and a review cadence focused on response times, ticket aging, and recurring quality issues. Assign one owner for vendor performance and remediation sign-off.
Establish operating rhythms
Set a simple cadence that forces action: a monthly site review for open issues and service performance issues, a regular vendor check-in for SLA performance and aging tickets, and a brief after-action review after major incidents. End each with clear owners and due dates.
Plan onboarding for new sites
Create a structured 30/60/90-day onboarding workflow for new facilities or acquisitions. Define who performs assessments, who validates baseline implementation, and who signs off on operational readiness.
Create a technology strategy: architecture principles plus managed-fleet operations
After defining who operates security services, standardize the structure and maintenance of the technology that powers those services. Treat the security estate as a managed fleet rather than a collection of isolated installations.
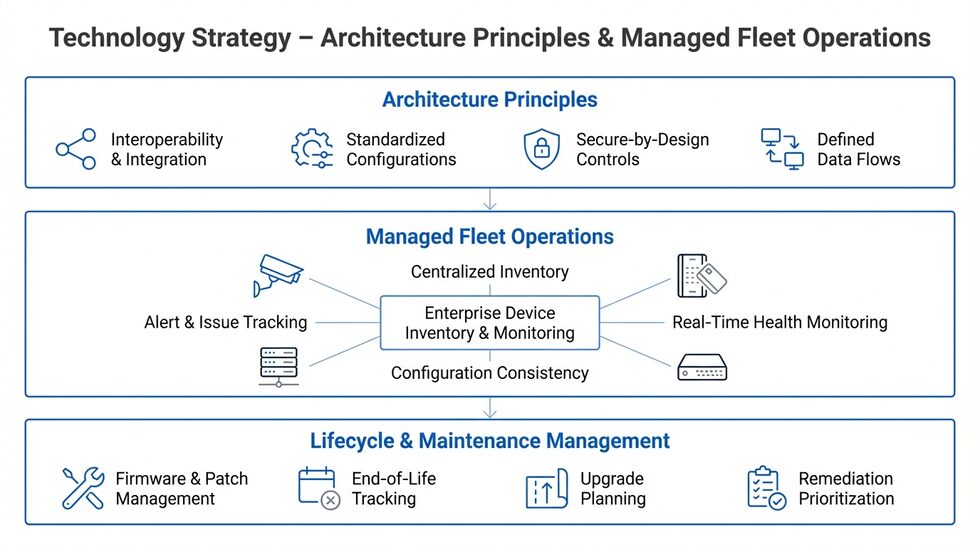
Architecture and managed fleet model for scalable enterprise security systems. (Source)
Define integration principles upfront
Set clear rules for how systems connect and exchange data. Require interoperability, consistent naming conventions, and defined event and evidence workflows. Avoid locking the program into isolated platforms that cannot scale or integrate with enterprise systems.
If you're inheriting a mixed estate, treat these principles as the target state and roll them in through a phased modernization plan. Start by classifying legacy systems into: keep (meets principles), integrate (acceptable in the short term with adapters), and replace (can't meet requirements or is near the end of support). "Grandfather" only with a documented expiry date and a minimum set of guardrails (standard naming, basic health monitoring, and a migration plan).
Maintain a single source of truth for the device estate
Create an authoritative inventory that records what is deployed, where it is located, who owns it, and its lifecycle status. Keep this inventory current and use it as the reference point for upgrades, lifecycle planning, and troubleshooting.
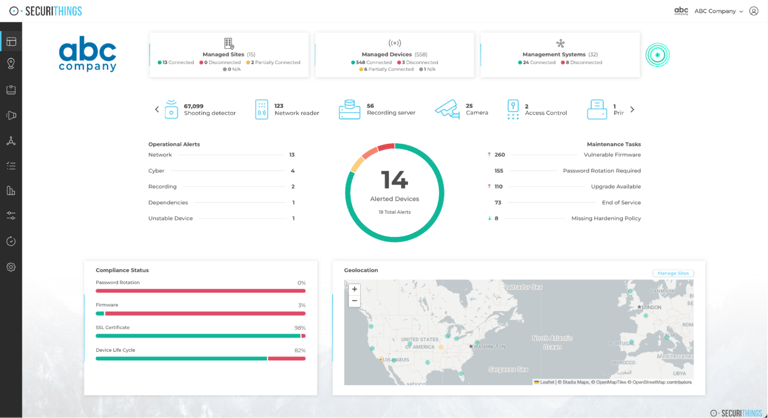
Enterprise-wide device inventory and health dashboard supporting managed-fleet operations. (Source)
Monitor health and configuration continuously
Require visibility into uptime, configuration drift, and recurring faults, but do not stop at monitoring alone. Define who reviews this information, how quickly issues must be triaged, and how remediation actions are carried out across the fleet. In physical security environments, teams often need to update passwords, firmware, certificates, and hardening settings directly, so health monitoring should be paired with workflows that support and simplify those changes. Do not rely on manual reporting from sites; build both monitoring and remediation into normal operations.
Plan lifecycle and refresh deliberately
Track end-of-life and end-of-support timelines early enough to act before devices become a risk. Use lifecycle data to sequence upgrades based on criticality, business impact, and replacement complexity, and avoid waiting until equipment is already unsupported. Where possible, pair lifecycle tracking with forward-looking recommendations so teams can identify which models should be replaced first and what replacement paths make the most sense. Replace reactive replacement cycles with predictable refresh planning.
Platforms that centralize inventory, health data, and lifecycle status across multiple sites, such as SecuriThings, can support this strategy by doing more than surfacing problems. They can help teams prioritize remediation, support configuration and firmware actions at scale, and provide earlier warning when devices are approaching EOL/EOS so planning starts before disruption occurs.
Build resilience and continuity requirements into the strategy
After defining how systems are structured and operated, make sure they continue to function when conditions are not normal. Build resilience requirements directly into the strategy instead of treating continuity as a separate exercise.
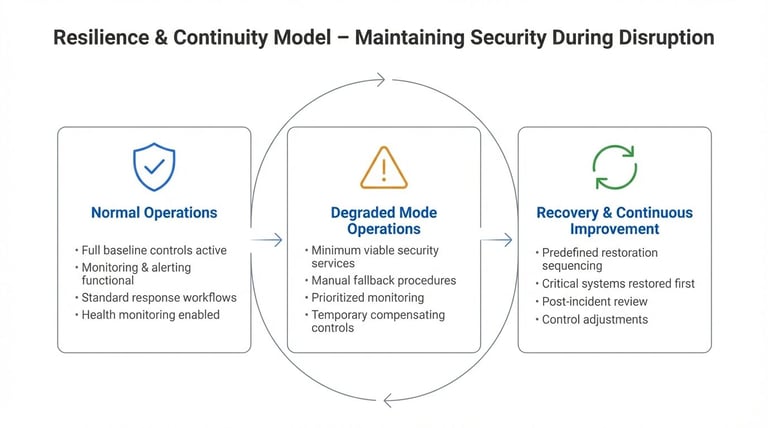
Continuity model for maintaining security during disruption
Define minimum viable security services
Identify what must remain operational during disruption. For each facility tier, specify the essential functions that cannot fail, such as access control for critical areas, monitoring capability, or logging for high-risk zones. Document these minimum services clearly so recovery priorities are predefined rather than debated during an incident.
Align these minimum services with your broader technology and vendor strategy. A single global vendor model can simplify standards, reporting, and recovery coordination, but may concentrate risk if that provider experiences systemic disruption. A regional or multi-vendor model can improve local execution and redundancy, but increases integration complexity and oversight requirements. Make the tradeoffs explicit and ensure your continuity planning accounts for how quickly each model can restore minimum viable services across sites.
Plan degraded-mode operations
Assume systems will fail at some point and define how teams operate when they do. Document fallback procedures, manual alternatives, escalation paths, and temporary controls. Keep these procedures practical and tested. Avoid overly complex contingencies that no one will execute under pressure.
Set recovery sequencing rules
Predefine how restoration happens. Determine which systems are restored first, who authorizes prioritization changes, and how progress is tracked. Align this sequencing with business criticality rather than technical convenience.
Exercise and adjust
Run periodic exercises that test not just incident response but system degradation scenarios such as power interruptions, connectivity loss, device outages, or vendor delays. Capture lessons and adjust procedures and recovery priorities based on observed gaps.
Operationalize compliance and privacy globally
Once systems and operating models are defined, formalize how data and evidence are handled across regions. Make compliance and privacy rules executable, not theoretical, and embed them into daily operations.
Define clear data handling rules
Document how video footage, access logs, and system records are retained, accessed, and shared. Specify retention periods, approval requirements for exports, and where records are stored. Keep rules consistent across sites, with documented regional variations only where legally required.
Make these rules easy to follow by training the people who touch footage and logs—GSOC operators, site security leads, investigators, and IT admins—on approved use cases, export/retention do's and don'ts, and escalation paths. Reinforce training with quick job aids (e.g., "when you can export," "who approves," "how to store evidence") so correct behavior is the default.
Control privileged access
Limit access to raw footage, system configurations, and sensitive logs. Assign named roles with defined permissions and require periodic reviews of privileged accounts. Track who accessed what and ensure access aligns with approved use cases.
Standardize evidence workflows
Define how incidents are documented, how evidence is preserved, and how it is transferred internally or externally. Keep documentation consistent across regions so cases can be reviewed or escalated without rework. Avoid informal exports or ad hoc storage locations.
Align vendors with compliance expectations
Require integrators, monitoring providers, and technology vendors to adhere to the same data-handling and security standards. Document expectations for storage location, subcontractor use, breach notification, and secure disposal of retired devices.
Run strategy with executive metrics, benchmarking, and a living roadmap
After defining structure, ownership, baselines, and resilience, keep the strategy active through measurable performance and disciplined prioritization. Treat the strategy as an operating system that is reviewed and adjusted on a predictable cadence.
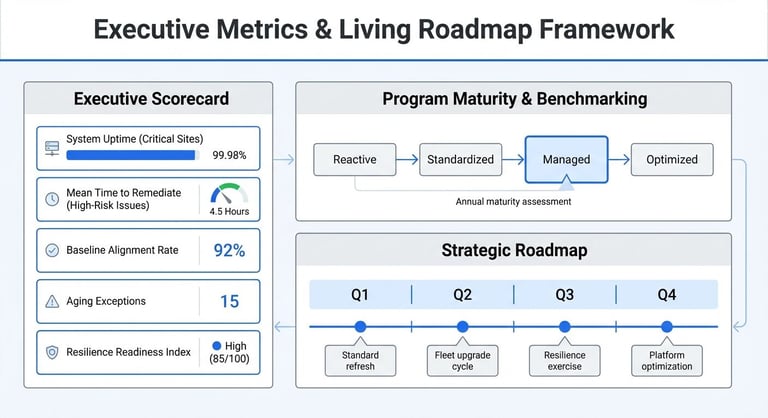
Leadership-level metrics and roadmap framework for sustained enterprise security performance.
Build an executive scorecard
Define a small set of metrics that reflect outcomes across people, operations, and technology, not just system health. Track a balanced mix, including priority incident impact (severity and recurrence), response performance for high-risk events, baseline alignment rates and aging exceptions, disruption readiness indicators, and technology reliability for critical sites (uptime and time to remediate high-priority issues). Keep the list short and review it consistently with leadership.
Benchmark maturity and close gaps
Periodically assess the program's progress against internal targets and external peers. Use the results to identify capability gaps, not to defend the current state. Focus on trends across sites rather than isolated data points.
Maintain a disciplined roadmap cadence
Translate scorecard insights into quarterly priorities. Sequence initiatives based on risk exposure, business impact, lifecycle triggers, and operational strain. Avoid adding new projects without retiring or reprioritizing existing ones. Review roadmap progress on a set cadence and adjust deliberately rather than reactively.
Refresh strategy inputs routinely
Update priorities based on incidents, audit findings, exercises, business expansion, and technology lifecycle milestones. Keep the roadmap aligned with actual operating conditions, not static planning assumptions.
Conclusion
A corporate physical security strategy becomes credible when it moves beyond principles and into disciplined execution. Define outcomes clearly, assign ownership, translate risk into enforceable baselines, structure a scalable operating model, and manage technology as an enterprise fleet rather than isolated systems. Build resilience into design decisions, formalize compliance expectations, and track performance with executive-level metrics that show measurable progress.
Keep the strategy alive by reviewing it on a predictable cadence and adjusting priorities based on real operating data, not assumptions. When leadership can see coverage, health, remediation trends, and risk exposure across sites, conversations shift from anecdotal updates to informed decisions.
A platform like SecuriThings makes this entire process much smoother. It gives your team a single, clear view, a dashboard of all your security devices across every location. You can quickly see what equipment you have, if it's healthy, and what issues need fixing. This translates your security strategy into real, measurable control and helps your organization continuously improve.

